How Apple accidentally broke my Spotify client
This month, after coming back from my time off, I turned on my work laptop and started catching up on everything that happened during my absence. Music makes this process more enjoyable, so I started up Spotify and started playing some tunes. I was very surprised (and mildly pissed) when playback abruptly stopped and Spotify seemingly went offline.
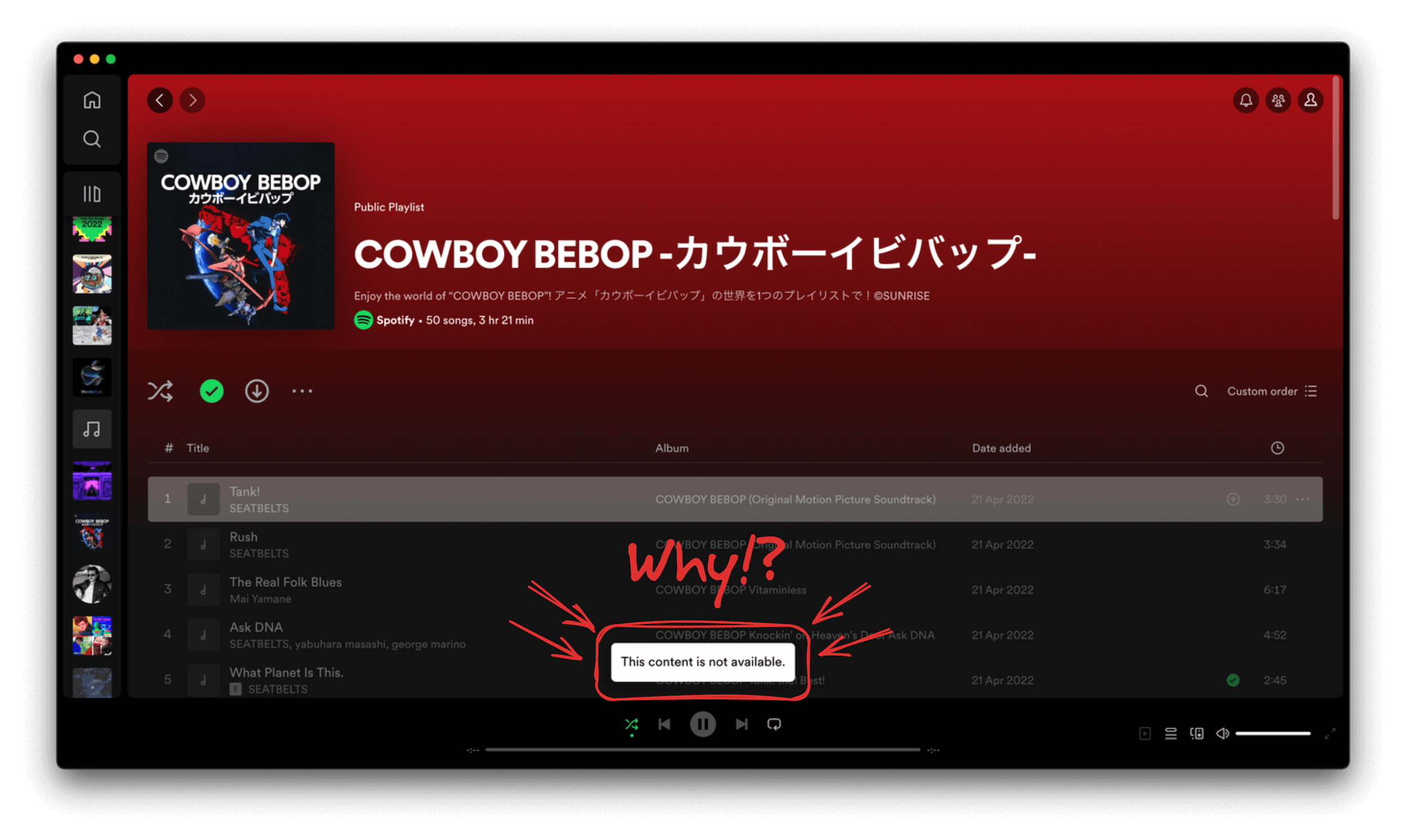
I immediately thought my network went offline or that - perhaps - Spotify was just having an outage. But in reality, my network was okay and Spotify was working just fine on my phone. Even more puzzling, I could do searches just fine on Spotify (even albums or songs that I never played before), but playback was disabled. Time to dig deeper!
First, I tried to see which temporary fix worked:
- Closing and reopening Spotify didn’t make any difference;
- Disabling and re-enabling Wi-Fi fixed the problem temporarily;
- Rebooting my machine also fixed the problem temporarily.
Gathering intel
After unsuccessfully scouring my system trying to find logs written by Spotify and a lot of Googling, I finally managed to find the flag that convinces it to save some logs:
/Applications/Spotify.app/Contents/MacOS/Spotify --log-file="$HOME/spotify.log"
When the issue reproduced again, I frantically checked the logs and found some very interesting lines:
16:37:36.805 I [f:388 ] Reachability changed from wlan (IP [192.168.1.x, fe80::xyz%en0, ...],
roaming false) to none (IP [192.168.1.x, fe80::xyz%en0, ...], roaming false)
...
16:37:36.819 I [connect:448] ConnectConnectivityListener: connection lost because
connectivity_manager->connectionType() == connectivity::kConnectionTypeNone
16:37:36.820 I [f:112 ] Connectivity policy changed from allow_all to disallow_all
The logs confirmed that Spotify was really convinced that my network disappeared out of the blue - so convinced that it disallowed all outgoing connections, thus breaking my playback. This connectivity check is clearly misbehaving, but where to start looking?
Spotify’s reachability check
Before considering going full reverse engineering on Spotify’s binary, I ran good ol’ strings on the binary looking for anything containing reachability:
$ strings /Applications/Spotify.app/Contents/MacOS/Spotify | grep -i 'reachability'
...
reachabilityForInternetConnection
...
void ReachabilityCallback(SCNetworkReachabilityRef, SCNetworkConnectionFlags, void *)
^{__SCNetworkReachability=}16@0:8
v24@0:8^{__SCNetworkReachability=}16
^{__SCNetworkReachability=}
Surprisingly, I got an entire function signature out of the binary - and it seems exactly what I was looking for. In fact, I recognized SCNetworkReachability from my iOS development era: this is an Apple API designed to “determine the status of a system’s current network configuration and the reachability of a target host”. Is it possible that this API is somehow misbehaving, causing Spotify to believe the network is down?
To figure it out, I first needed to understand how Spotify used this API in the first place. Time to whip out the big guns - aka a debugger. There are three entry points to the SCNetworkReachability API, allowing to check for reachability of either an address, address pair, or hostname. I hooked all of them just to be sure:
$ lldb /Applications/Spotify.app/Contents/MacOS/Spotify
(lldb) target create "/Applications/Spotify.app/Contents/MacOS/Spotify"
Current executable set to '/Applications/Spotify.app/Contents/MacOS/Spotify' (arm64).
(lldb) b SCNetworkReachabilityCreateWithName
Breakpoint 1: where = SystemConfiguration`SCNetworkReachabilityCreateWithName, address = 0x000000018125a928
(lldb) b SCNetworkReachabilityCreateWithAddressPair
Breakpoint 2: where = SystemConfiguration`SCNetworkReachabilityCreateWithAddressPair, address = 0x0000000181291358
(lldb) b SCNetworkReachabilityCreateWithAddress
Breakpoint 3: where = SystemConfiguration`SCNetworkReachabilityCreateWithAddress, address = 0x000000018125c4cc
Then, I launched the process and crossed my fingers to see a hit:
(lldb) r
Process 2952 launched: '/Applications/Spotify.app/Contents/MacOS/Spotify' (arm64)
Process 2952 stopped
* thread #12, name = 'NetworkConfigWatcher', stop reason = breakpoint 3.1
frame #0: 0x000000018bd084cc SystemConfiguration`SCNetworkReachabilityCreateWithAddress
SystemConfiguration`SCNetworkReachabilityCreateWithAddress:
Boom! Spotify is definitely calling SCNetworkReachabilityCreateWithAddress. But what address is it checking for, though? The second argument passed to this function is a struct sockaddr, which looks like this:
struct sockaddr {
__uint8_t sa_len; /* 1 byte */
sa_family_t sa_family; /* 1 byte */
/* the rest of the data depends on what kind of sockaddr this is */
};
Spotify is almost certainly checking for an IPv4 address, so I expected sa_family to be AF_INET (2). I asked LLDB:
(lldb) p/x *(char*)($arg2 + 1)
(char) 0x02
Yep. The layout then looks like:
struct sockaddr_in {
__uint8_t sin_len;
sa_family_t sin_family;
in_port_t sin_port; /* 2 bytes */
struct in_addr sin_addr; /* 4 bytes */
};
Thus, port and address are:
(lldb) p/x *(uint16_t*)($arg2 + 2)
(uint16_t) 0x0000
(lldb) p/x *(uint32_t*)($arg2 + 4)
(uint32_t) 0x00000000
Spotify is calling SCNetworkReachabilityCreateWithAddress with 0.0.0.0:0 as the address to check. This is actually a common and somewhat discouraged pattern. Quoting Apple:
The Reachability APIs […] are intended for diagnostic purposes after identifying a connectivity issue. Many apps incorrectly use these APIs to proactively check for an Internet connection by calling the
SCNetworkReachabilityCreateWithAddressmethod and passing it an IPv4 address of0.0.0.0, which indicates that there is a router on the network. However, the presence of a router doesn’t guarantee that an Internet connection exists. […] If you must check for network availability, […] call theSCNetworkReachabilityCreateWithNamemethod and pass it a hostname instead.
Sounds sensible. The thread name that LLDB reports is NetworkConfigWatcher, so maybe this API is not actually used to know whether the machine is online or not. Perhaps Spotify is also using SCNetworkReachabilityCreateWithName?
(lldb) c
Process 2952 resuming
Process 2952 stopped
* thread #24, name = 'Core Thread', stop reason = breakpoint 1.1
frame #0: 0x000000018bd06928 SystemConfiguration`SCNetworkReachabilityCreateWithName
SystemConfiguration`SCNetworkReachabilityCreateWithName:
Aha! They seem to be indeed using both. And the hostname they’re using is…
(lldb) e (char*)($arg2)
(char *) $26 = 0x00000001016f111b "www.spotify.com"
Excellent - I now knew that Spotify checks for reachability of the www.spotify.com hostname as well as general “router” reachability using the address 0.0.0.0. Based on the function signature I found earlier, they are using the asynchronous callback-based API to receive updates on any network connectivity change. But I still had no idea whether this was the actual cause of the issue and why…
Deep dive into Reachability
With a reasonable doubt that the underlying issue stems indeed from SCNetworkReachability, I decided to get out from the debugger and try to build a reproducer. I did not have Xcode installed on my work laptop, though, which would have taken hours to download, unpack and run.
Fortunately, further spelunking led me to scutil1, a command line tool typically used to manage DNS configurations, but which also contains this very interesting mode:
scutil -r [-W] { nodename | address | local-address remote-address }Check the network reachability of the specified host name, IP address, or a pair of local and remote IP addresses. […] The reachability can also be monitored by specifying the -W (watch) option.
Seems like exactly what I was looking for! Basically a CLI for SCNetworkReachability. I tried it out with 0.0.0.0 first:
$ scutil -r -W 0.0.0.0
0: direct
<SCNetworkReachability 0x1336056b0 [0x1e57ef9a0]> {default path}
Reachable
1: start
<SCNetworkReachability 0x133605880 [0x1e57ef9a0]> {default path}
2: on runloop
<SCNetworkReachability 0x133605880 [0x1e57ef9a0]> {default path, flags = 0x00000002, if_index = 18}
Reachable
This looked… okay? “Reachable” certainly seems to indicate nothing is wrong. Subsequently, I tried the host reachability with the domain I found before:
$ scutil -r -W www.spotify.com
0: direct
<SCNetworkReachability 0x156605740 [0x1e57ef9a0]> {name = www.spotify.com}
Reachable
1: start
<SCNetworkReachability 0x156605a00 [0x1e57ef9a0]> {name = www.spotify.com}
2: on runloop
<SCNetworkReachability 0x156605a00 [0x1e57ef9a0]>
{name = www.spotify.com (DNS query active),
flags = 0x00000002, if_index = 18}
Reachable
*** 20:10:12.715
3: callback w/flags=0x00000002 (info="by name")
<SCNetworkReachability 0x156605a00 [0x1e57ef9a0]>
{name = www.spotify.com (in progress, 35.186.224.25, 2600:1901:1:c36::),
flags = 0x00000002, if_index = 18}
Reachable
*** 20:10:12.740
4: callback w/flags=0x00000000 (info="by name")
<SCNetworkReachability 0x156605a00 [0x1e57ef9a0]>
{name = www.spotify.com (complete, no addresses),
flags = 0x00000000, if_index = 18}
Not ReachableI was thrilled. Finally some evidence that seems to indicate that Spotify is innocent and that there’s a deeper problem to be unfolded…
Based on the output, it seems like the API starts by saying the host is reachable and it proceeds to run a DNS query (“DNS query active”), still reporting that the domain is reachable. While still in progress, the query seems to return the addresses for the domain until it shockingly finishes with “no addresses” and a verdict of “Not Reachable”.
I immediately thought my DNS resolver was acting up, so I tried to resolve the domain manually:
$ nslookup www.spotify.com
Server: ::1
Address: ::1#53
Non-authoritative answer:
www.spotify.com canonical name = edge-web.dual-gslb.spotify.com.
Name: edge-web.dual-gslb.spotify.com
Address: 35.186.224.25
Yeah, that would have been too easy. The resolver seems to be working perfectly fine - it looks like this is a standard CNAME pointing to edge-web.dual-gslb.spotify.com. Even running dig to request both A and AAAA records did not show evidence of any problem.
If you remember, at the beginning I mentioned that Spotify would seem to work after disabling and re-enabling my Wi-Fi interface. So how does the output of scutil look like when I do that?
$ scutil -r -W www.spotify.com
0: direct
<SCNetworkReachability 0x140704ff0 [0x1e88179a0]> {name = www.spotify.com}
Reachable
1: start
<SCNetworkReachability 0x1407052a0 [0x1e88179a0]> {name = www.spotify.com}
2: on runloop
<SCNetworkReachability 0x1407052a0 [0x1e88179a0]>
{name = www.spotify.com (DNS query active),
flags = 0x00000002, if_index = 18}
Reachable
*** 0:59:30.105
3: callback w/flags=0x00000002 (info="by name")
<SCNetworkReachability 0x1407052a0 [0x1e88179a0]>
{name = www.spotify.com (complete, 35.186.224.25, 2600:1901:1:c36::),
flags = 0x00000002, if_index = 18}
ReachableMysteriously, everything seemed to be fine now - scutil was able to resolve the domain just fine. However, re-running it after a while produced the same weird “Not Reachable” verdict as above.
At this point I was stumped. Googling around led me to the source code of SCNetworkReachability, which I thought would have been the key to figure out the solution. In reality, other than learning of “Crazy Ivan 46”2, the DNS resolution seemed to happen using private and opaque nw_resolver APIs.
In an act of desperation, I opened Console.app on my laptop and started checking out the logs during another execution of scutil. A lightbulb lit up in my head when I saw some log traffic from mDNSResponder.
mDNSResponder: here be dragons
mDNSResponder, also known as Bonjour, is the macOS system daemon historically responsible for Multicast DNS, i.e. things like finding and resolving other devices on your network via a special .local TLD.
However, mDNSResponder also handles unicast (“normal”) DNS - and it handles all DNS queries that are not explicitly made via a resolver. In fact, it also handles queries done via getaddrinfo() through a UNIX domain socket on /var/run/mDNSResponder as well as a dedicated XPC service named com.apple.dnssd.service.
Here’s the first line I saw in the Console logs:
20:10:12.713635+0000 [R17547] getaddrinfo start -- flags: 0xC000D000, ifindex: 0, protocols: 0, hostname: <mask.hash: 'z5DRt/5oli3kmBV+AaKTOg=='>, options: 0x8 {use-failover}, client pid: 20129 (scutil)
This is the entry point of the DNS resolution request issued by SCNetworkReachability (relatively easy to spot by the caller’s process name at the end, scutil). Did you spot the weird value of the hostname field? That is, <mask.hash: 'z5DRt/5oli3kmBV+AaKTOg=='>. Let me go through a small digression…
Apple Unified Logging
Apple has done a lot of work to unify their logging interface under one streamlined API, os_log.
In order to make it less likely for PII to make it into diagnostic reports, all format string values are redacted with the string <private> unless you explicitly mark them as public.
This makes little sense when you’re trying to debug an issue on your system, so at the beginning they also provided the option to toggle this redaction via a special log command. Unfortunately, this convenient command no longer works since a few major macOS versions - the only alternative being a “configuration profile” that toggles a poorly documented system-wide flag that is supposed to enable private logging again.
Since macOS Big Sur (11), Apple also allows developer to redact values with a hash generated from the input string. Unlike the opaque <private> redaction, this allows you to at least figure out whether the log messages are referring to the same thing (since the hashes will be the same).
Sadly, macOS Sonoma has made the “private” logging story apparently even worse. During the course of this story, I was unable to make any configuration profile (even signed!) work for “unmasking” logs. Via some advanced dyld library injection I was able to at least enable private logging on my SIP-less personal laptop, but this still didn’t unmask the hashed values, making logs practically useless anyway.
This was the single biggest hurdle for this debugging journey. If I were able to unmask these logs in a timely manner when debugging this on my work laptop, I would have figured out the root cause much sooner. But I really didn’t want to reverse engineer logd to figure out what else needed to be done to make it work… If you know of any tricks, my contacts are at the bottom of the post.
Update (2025-04-12): A reader informed me of the existence of an official Apple signed configuration profile specific to mDNSResponder that allows to unmask redacted values from the logs. This should be immensely valuable for someone looking to understand the inner workings of mDNSResponder. Thank you, Ilya!
So, what is mDNSResponder doing then?
From the logs, it looked like mDNSResponder was going through the codepath to follow a CNAME - which is expected, given that www.spotify.com is indeed a CNAME:
20:10:12.713690+0000 [R17547->Q54433] Question for <mask.hash: 'Ki6nMX/bXTCT2/KzwHIjYQ=='> (AAAA) assigned DNS service 430
20:10:12.713713+0000 [R17547->Q65240] Question for <mask.hash: 'Ki6nMX/bXTCT2/KzwHIjYQ=='> (Addr) assigned DNS service 430
20:10:12.713836+0000 [R17547->Q54433] AnswerQuestionByFollowingCNAME: 0x15b408ba0 <mask.hash: 'Ki6nMX/bXTCT2/KzwHIjYQ=='> (AAAA) following CNAME referral 0 for <mask.hash: 'imxMIKShQz6ibN88bU8EGw=='>
20:10:12.713932+0000 [R17547->Q9196] Question for <mask.hash: 'nAmRVDb4e0hbk+/j7VbWyw=='> (AAAA) assigned DNS service 430
20:10:12.713963+0000 [R17547->Q65240] AnswerQuestionByFollowingCNAME: 0x15b408f50 <mask.hash: 'Ki6nMX/bXTCT2/KzwHIjYQ=='> (Addr) following CNAME referral 0 for <mask.hash: 'imxMIKShQz6ibN88bU8EGw=='>
20:10:12.714169+0000 <private>
20:10:12.714308+0000 <private>
But here comes the surprising part:
20:10:12.714489+0000 [R17547->Q9196] getaddrinfo result -- event: add, ifindex: 0, name: BBBzimzl, type: AAAA, rdata: BBQBqWtg, expired: yes
20:10:12.714524+0000 [R17547->Q47948] getaddrinfo result -- event: add, ifindex: 0, name: BBBzimzl, type: A, rdata: BBwGxJEp, expired: yes
20:10:12.740246+0000 [R17547->Q21452] getaddrinfo result -- event: add, ifindex: 0, name: BBlPUROb, type: AAAA, rdata: <none>, reason: nxdomain
20:10:12.740309+0000 [R17547->Q37810] getaddrinfo result -- event: add, ifindex: 0, name: BBlPUROb, type: A, rdata: <none>, reason: nxdomain
20:10:12.740592+0000 [R17547] getaddrinfo stop -- hostname: <mask.hash: 'z5DRt/5oli3kmBV+AaKTOg=='>, client pid: 20129 (scutil)
The XPC call initially returns the A and AAAA records with the right addresses, but marked as expired. Shortly after, it returns the same records with the result NXDOMAIN, i.e. “no such domain”. This matches with the “no addresses” we saw in the output of scutil, but it’s still extremely surprising: how come that mDNSResponder seems to have two perfectly valid (cached? but expired) records, which get replaced by seemingly invalid ones?
Sniffing DNS traffic and more mDNSResponder shenanigans
At this point, my priority was to determine whether the NXDOMAIN I was seeing in the logs was genuine or fabricated by mDNSResponder as part of some other faulty logic.
The DNS configuration on my work laptop has two resolvers:
::1, pointing to a resolver listening onlocalhostthat tunnels DNS traffic through DNS over HTTPS to dns.google.8.8.8.8as a fallback resolver.
I started tcpdump on the loopback interface:
$ sudo tcpdump -vvv -i lo0 -n port 53
tcpdump: listening on lo0, link-type NULL (BSD loopback), snapshot length 524288 bytes
I then reran the scutil command, bracing myself to see some juicy DNS traffic:
<crickets>
Welp, I got absolutely nothing from tcpdump. For a while, I was gaslighted into believing that the DNS queries I saw in the logs and in scutil were never happening. Fortunately, I got a couple of hints - first, mDNSResponder sporadically logged lines similar to Sent 128-byte query #1 to BBpSYjZU over HTTPS via any/0. Then, whenever I sent a SIGHUP to mDNSResponder3, I saw some very interesting traffic on tcpdump (some parts stripped for brevity):
19:55:55.378808 IP6 (...) ::1.57821 > ::1.53: 52355+ Type64? _dns.resolver.arpa. (36)
19:55:55.449478 IP6 (...) ::1.53 > ::1.57821: 52355* q: Type64? _dns.resolver.arpa. 2/0/4 _dns.resolver.arpa.
[1d] Type64, _dns.resolver.arpa.
[1d] Type64 ar: dns.google.
[1d] A 8.8.8.8, dns.google.
[1d] A 8.8.4.4, dns.google.
[1d] AAAA 2001:4860:4860::8888, dns.google.
[1d] AAAA 2001:4860:4860::8844
macOS was making a Type64 DNS request to _dns.resolver.arpa and getting a bunch of records back. But what is even Type64? Alas, I clearly fell behind on how DNS has evolved in the past few years. Well, it turns out that this is a SVCB record, intended to be more or less a DNS-layer alternative to ALPN.
Still sounds like jargon? Yeah, I know. Cloudflare has a great explainer on the general use case for the new SVCB and HTTPS records, but this is a special case.
This SVCB query to _dns.resolver.arpa is used to figure out whether your (unencrypted) DNS server also has an encrypted variant (e.g. DNS over HTTPS), and allows mDNSResponder to silently switch to it without you even noticing - free security!4 This process is called designated resolver discovery. Here’s a better rendition of how the Google DNS record looks.
Fascinatingly, the IEEE draft above also specifies how to protect against rogue DNS servers sending out untrustworthy designated resolvers. The system will only accept a designated resolver if it contains the IP of the system resolver as part of its X509 certificate alternative names:
$ openssl s_client -showcerts -connect dns.google:443 </dev/null 2>/dev/null | \
openssl x509 -text | \
grep 'X509v3 Subject Alternative Name' -A 1
X509v3 Subject Alternative Name:
DNS:dns.google, DNS:dns.google.com, DNS:*.dns.google.com, DNS:8888.google, DNS:dns64.dns.google,
IP Address:8.8.8.8, IP Address:8.8.4.4,
IP Address:2001:4860:4860:0:0:0:0:8888, IP Address:2001:4860:4860:0:0:0:0:8844,
IP Address:2001:4860:4860:0:0:0:0:6464, IP Address:2001:4860:4860:0:0:0:0:64
The actual problem
After gently convincing mDNSResponder to not encrypt all of my DNS traffic, I re-ran scutil and saw this in tcpdump:
01:01:41.980162 IP6 (...) ::1.61877 > ::1.53: 51899+ AAAA? www.spotify.com.0.1.168.192.in-addr.arpa. (58)
01:01:41.980288 IP6 (...) ::1.62050 > ::1.53: 13223+ A? www.spotify.com.0.1.168.192.in-addr.arpa. (58)
01:01:41.991388 IP6 (...) ::1.53 > ::1.61877: 51899 NXDomain q: AAAA? www.spotify.com.0.1.168.192.in-addr.arpa. 0/0/0 (58)
01:01:41.993209 IP6 (...) ::1.53 > ::1.62050: 13223 NXDomain q: A? www.spotify.com.0.1.168.192.in-addr.arpa. 0/0/0 (58)
Woah! mDNSResolver was trying to resolve www.spotify.com.0.1.168.192.in-addr.arpa - and the resolver was obviously returning NXDOMAIN. At a glance, 0.1.168.192.in-addr.arpa looked like what you would resolve to perform a reverse DNS lookup – but that does not make any sense here. Given that it’s appended to the end of Spotify’s domain name, could it possibly have been specified as a search domain anywhere?
$ scutil --dns | grep -i domain
domain : local
domain : 254.169.in-addr.arpa
domain : 8.e.f.ip6.arpa
domain : 9.e.f.ip6.arpa
domain : a.e.f.ip6.arpa
domain : b.e.f.ip6.arpa
Of course not. Even the macOS settings agreed with me (for once):
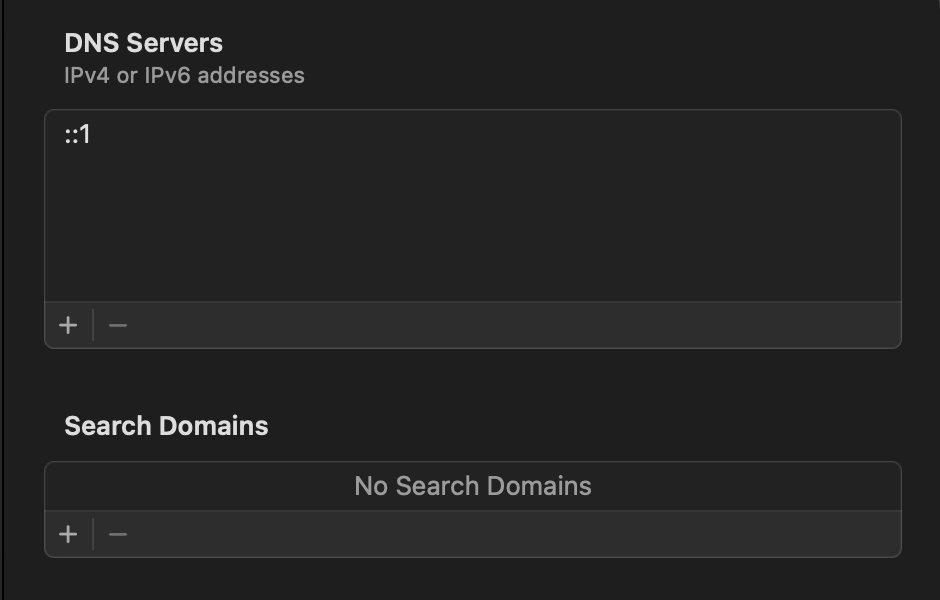
At this point, I felt like I was at a dead end. There were too many hurdles to get to the root of this:
- My work laptop had SIP enabled and a locked recovery mode, which made it impossible to disable it. In turn, this made unmasking the logs and attaching a debugger to
mDNSResponderimpossible, greatly complicating any kind of debugging. - I could not reproduce the issue on my personal laptop regardless of how hard I tried.
- I went through the (open) source code of
mDNSRespondertrying to understand how it works, the codepaths my work laptop took based on the (redacted) logs and looking at the commit history to see if any of the latest commits made any suspicious change. Given that the logs showed valid but expired records being returned first and invalid ones immediately after, I also suspected some kind of bug in the caching logic. In the end, the only thing I gained from this deep dive is a huge headache due to how convoluted the codebase is. - I became convinced that my local resolver (built and deployed by my company) was somehow triggering a bug in
mDNSResponder, given that it modified the system DNS configuration and added some EDNS0 options to resolved records. I got so deep into this that I compiled it locally, debugged it extensively and tweaked various parts of the DNS resolution code. Nope.- In hindsight, this was very much of a wasted effort given that the problem reproduced with any resolver.
Light at the end of the tunnel
In an act of desperation, I checked the man page of mDNSResponder to try and find some other useful mechanism for debugging. The man page contains surprisingly useful information, including the following snippet:
A SIGUSR1 signal toggles additional logging, with Warning and Notice enabled by default:
% sudo killall -USR1 mDNSResponderOnce this logging is enabled, users can additionally use syslog(1) to change the log filter for the process. For example, to enable log levels Emergency - Debug:
% sudo syslog -c mDNSResponder -dA SIGUSR2 signal toggles packet logging:
% sudo killall -USR2 mDNSResponderA SIGINFO signal will dump a snapshot summary of the internal state to /var/log/system.log:
% sudo killall -INFO mDNSResponder
Needless to say, the extra logging tip was not very helpful due to the unified logging redaction. However, I was deeply hopeful for the described behavior of SIGINFO, so I tried it immediately:
$ sudo killall -INFO mDNSResponder
$ tail -n 20 /var/log/system.log
<crickets>
Again, that would have been too easy, right? Looking at Console.app, mDNSResponder helpfully replied with:
Sending SIGINFO to mDNSResponder daemon is deprecated. To trigger state dump, please use ‘dns-sd -O’, enter ‘dns-sd -h’ for more information
Hyped again, I immediately tried that:
$ dns-sd -O
XPC service returns error, description: Client must be running as root
$ sudo dns-sd -O # dammit
XPC service returns error, description: State dump is only enabled in internal builds
So close, but so far. Desperate, another glance at the man page revealed this section at the end:
OPTIONAL ARGUMENTS
mDNSResponder accepts the following optional arguments:
-AlwaysAppendSearchDomainsAppend search domains for multi-labeled Partially Qualified Domain Name as well as single-labeled Partially Qualified Domain Name. This argument is not recommended because of the extra DNS traffic it generates and its adverse effect on battery life.
[…]
To cause mDNSResponder to run with these optional arguments when it launches on OS X 10.11 (El Capitan) and later, set the
AlwaysAppendSearchDomainsorNoMulticastAdvertisementsboolean keys to true in/Library/Preferences/com.apple.mDNSResponder.plistand reboot.
Hmm, search domains. Could it possibly have been…?
$ defaults read /Library/Preferences/com.apple.mDNSResponder.plist
{
AlwaysAppendSearchDomains = 1;
}
I audibly gasped when I saw this option being set on my work laptop. Given the previous disappointments, I still held my enthusiasm before checking whether it was the actual cause:
# disable the flag and restart mDNSResponder
$ sudo defaults write /Library/Preferences/com.apple.mDNSResponder.plist AlwaysAppendSearchDomains -bool no
$ sudo killall mDNSResponder
# fingers crossed...
$ scutil -r -W www.spotify.com
<snip>
*** 1:32:10.411
3: callback w/flags=0x00000002 (info="by name")
<SCNetworkReachability 0x1407052a0 [0x1e88179a0]>
{name = www.spotify.com (complete, 35.186.224.25, 2600:1901:1:c36::),
flags = 0x00000002, if_index = 18}
Reachable
$ sleep 120 # enough time to trigger the issue before
$ scutil -r -W www.spotify.com
<snip>
Reachable
Yes!! Finally, the solution. An obscure flag (likely set by the company’s MDM software) is breaking proper DNS resolution for SCNetworkReachability.
But why?
Relieved to finally have my playlists again, I still had many questions about the nature of the issue and I knew I wouldn’t have been satisfied if I didn’t answer them:
- What is going on here and why does it only happen sporadically?
- Why does it not affect most DNS requests? I had no problems with general browsing on my work laptop. Why specifically
SCNetworkReachabilityand/or Spotify? - What changed? This issue only started to happen recently - perhaps after the last system update. This option has been enabled on laptops for the last 10 years.
With a way to reproduce the problem, I switched to my personal laptop, enabled the same flag and confirmed that it triggered the issue again. This time, though, I could disable SIP and whip out the big guns.
But first, some static analysis. Looking at the source code of mDNSResponder, this option is used by both entry points for DNS resolution requests to determine whether to flip the appendSearchDomains flag on DNS queries:
if (!StringEndsWithDot(inParams->hostnameStr) && (AlwaysAppendSearchDomains || DomainNameIsSingleLabel(&hostname)))
{
appendSearchDomains = mDNStrue;
}
The domain SCNetworkReachability is trying to resolve (www.spotify.com) does not contain a dot at the end, so this flag is indeed flipped.
Next, the most relevant use of this flag seems to be in QueryRecordOpCallback - the callback invoked at the end of DNS resolutions:
else if (inAnswer->RecordType == kDNSRecordTypePacketNegative) // (1)
{
if (inQuestion->TimeoutQuestion && ((GetTimeNow(m) - inQuestion->StopTime) >= 0)) // (2)
/* snip */
else
{
if (inQuestion->AppendSearchDomains && (op->searchListIndex >= 0) && inAddRecord) // (3)
{
domain = NextSearchDomain(op);
if (domain || DomainNameIsSingleLabel(op->qname))
{
QueryRecordOpStopQuestion(inQuestion);
QueryRecordOpRestartUnicastQuestion(op, inQuestion, domain);
goto exit;
}
}
Ignoring the other conditions before this else if, the code first checks if the answer is a “negative answer” (1). This is jargon to indicate a NXDOMAIN or any other failure returned by the resolver. Then, the code checks whether the question timed out (2), and if not it checks (3):
- Whether
appendSearchDomainsis enabled AND - Whether the search domain list index is not negative (i.e. if there is any search domain) AND
- Whether this is an “add” request, other jargon to indicate a normal DNS request.
If those conditions match, mDNSResponder gets the next search domain from a linked list and issues another DNS request using the domain. Based on this summary analysis, it looks like the conditions in (3) would indeed be satisfied: but where would the negative answer (1) be coming from? It can’t be the NXDOMAIN resulting from the incorrect DNS query, since this logic is invoked for DNS responses. I was looking for something calling NextSearchDomain before making the DNS request, not after handling the response. Something doesn’t look right…
lldb should once again be able to clear up any doubts:
$ sudo lldb
(lldb) process attach -n mDNSResponder
Process 468 stopped
...
Target 0: (mDNSResponder) stopped.
Executable module set to "/usr/sbin/mDNSResponder".
Architecture set to: arm64e-apple-macosx-.
(lldb) c
Process 468 resuming
(lldb) b NextSearchDomain
Breakpoint 1: where = mDNSResponder`NextSearchDomain, address = 0x0000000100f72df4
And after invoking scutil again…
Process 468 stopped
* thread #2, stop reason = breakpoint 1.1
frame #0: 0x0000000100f72df4 mDNSResponder`NextSearchDomain
mDNSResponder`NextSearchDomain:
-> 0x100f72df4 <+0>: pacibsp
0x100f72df8 <+4>: sub sp, sp, #0x70
0x100f72dfc <+8>: stp x28, x27, [sp, #0x10]
0x100f72e00 <+12>: stp x26, x25, [sp, #0x20]
Target 0: (mDNSResponder) stopped.
Excellent! So what is going on here?
(lldb) bt
* thread #2, stop reason = breakpoint 1.1
* frame #0: 0x0000000100f72df4 mDNSResponder`NextSearchDomain
frame #1: 0x0000000100f72dac mDNSResponder`QueryRecordOpEventHandler + 964
frame #2: 0x0000000100eaa91c mDNSResponder`mDNS_Execute + 7964
frame #3: 0x0000000100ea5f0c mDNSResponder`KQueueLoop + 772
frame #4: 0x000000018df12034 libsystem_pthread.dylib`_pthread_start + 136
Hmm… wait, what? This call is coming from QueryRecordOpEventHandler, but there’s no trace of NextSearchDomain being called in the source code I was looking at. Also, there’s a log message supposed to be logged when entering the suspicious gotExpiredCNAME codepath, but I saw none in Console.app.5
mDNSlocal void QueryRecordOpEventHandler(DNSQuestion *const inQuestion, const mDNSQuestionEvent event)
{
QueryRecordOp *const op = (QueryRecordOp *)inQuestion->QuestionContext;
switch (event)
{
case mDNSQuestionEvent_NoMoreExpiredRecords:
if ((inQuestion->ExpRecordPolicy == mDNSExpiredRecordPolicy_UseCached) && op->gotExpiredCNAME)
{
// If an expired CNAME record was encountered, then rewind back to the original QNAME.
QueryRecordOpStopQuestion(inQuestion);
LogRedact(MDNS_LOG_CATEGORY_DEFAULT, MDNS_LOG_INFO,
"[R%u->Q%u] Restarting question that got expired CNAMEs -- current name: " PRI_DM_NAME
", original name: " PRI_DM_NAME ", type: " PUB_DNS_TYPE,
op->reqID, mDNSVal16(inQuestion->TargetQID), DM_NAME_PARAM(&inQuestion->qname), DM_NAME_PARAM(op->qname),
DNS_TYPE_PARAM(inQuestion->qtype));
op->gotExpiredCNAME = mDNSfalse;
AssignDomainName(&inQuestion->qname, op->qname);
inQuestion->ExpRecordPolicy = mDNSExpiredRecordPolicy_Immortalize;
#if MDNSRESPONDER_SUPPORTS(APPLE, QUERIER)
mDNSPlatformMemCopy(inQuestion->ResolverUUID, op->resolverUUID, UUID_SIZE);
#endif
// ??? where is NextSearchDomain?
QueryRecordOpStartQuestion(op, inQuestion);
}
break;
}
}I was utterly confused. I double checked the disassembly, which shows that QueryRecordOpStartQuestion is not even called:
(lldb) frame select 1
frame #1: 0x0000000100f72dac mDNSResponder`QueryRecordOpEventHandler + 964
mDNSResponder`QueryRecordOpEventHandler:
...
(lldb) disass
mDNSResponder`QueryRecordOpEventHandler:
...
0x100f72c68 <+640>: adr x3, #0x48d6e ; "[R%u->Q%u] Restarting question that got expired CNAMEs -- current name: %{sensitive, mask.hash, mdnsresponder:domain_name}.*P, original name: %{sensitive, mask.hash, mdnsresponder:domain_name}.*P, type: %{mdns:rrtype}d"
...
0x100f72da8 <+960>: bl 0x100f72df4 ; NextSearchDomain
-> 0x100f72dac <+964>: mov x2, x0
0x100f72db0 <+968>: b 0x100f72db8 ; <+976>
0x100f72db4 <+972>: mov x2, #0x0
0x100f72db8 <+976>: mov x0, x20
0x100f72dbc <+980>: mov x1, x19
0x100f72dc0 <+984>: bl 0x100f72fe4 ; QueryRecordOpRestartUnicastQuestion
; ??? where is QueryRecordOpStartQuestion?
...I stared at this for a while, then it dawned on me. Was I looking at the wrong source code? Perhaps for an old version? I scrambled to the Apple Open Source page, found the mDNSResponder release for macOS 14.2 and I went pale when I saw the link:
https://github.com/apple-oss-distributions/mDNSResponder/tree/mDNSResponder-2200.60.25.0.4
Damn. The latest version is on a separate branch – not on main where all of my tabs were pointing at. Even sadder, I think I started from this (correct) link, but immediately proceeded to use GitHub Search to orient myself around, which resets the branch.
This mDNSResponder release is from last month, which makes it a lot more suspicious. And indeed, just viewing the diff for the last commit immediately reveals the bug:
diff --git a/mDNSShared/ClientRequests.c b/mDNSShared/ClientRequests.c
index a31f2bd..77c8cb2 100644
--- a/mDNSShared/ClientRequests.c
+++ b/mDNSShared/ClientRequests.c
@@ -469,7 +469,16 @@ mDNSlocal void QueryRecordOpEventHandler(DNSQuestion *const inQuestion, const mD
#if MDNSRESPONDER_SUPPORTS(APPLE, QUERIER)
mDNSPlatformMemCopy(inQuestion->ResolverUUID, op->resolverUUID, UUID_SIZE);
#endif
- QueryRecordOpStartQuestion(op, inQuestion);
+ const domainname *domain = mDNSNULL;
+ if (inQuestion->AppendSearchDomains && (op->searchListIndex >= 0))
+ {
+ // If we're appending search domains, the DNSQuestion needs to be retried without Optimistic DNS,
+ // but with the search domain we just used, so restore the search list index to avoid skipping to
+ // the next search domain.
+ op->searchListIndex = op->searchListIndexLast;
+ domain = NextSearchDomain(op);
+ }
+ QueryRecordOpRestartUnicastQuestion(op, inQuestion, domain);
}
break;
}
@@ -798,6 +807,7 @@ mDNSlocal void QueryRecordOpCallback(mDNS *m, DNSQuestion *inQuestion, const Res
if (inQuestion->AppendSearchDomains)
{
op->searchListIndex = 0; // Reset search list usage
+ op->searchListIndexLast = 0;
domain = NextSearchDomain(op);
}
QueryRecordOpRestartUnicastQuestion(op, inQuestion, domain);
@@ -894,6 +904,7 @@ mDNSlocal void QueryRecordOpResetHandler(DNSQuestion *inQuestion)
inQuestion->InterfaceID = op->interfaceID;
}
op->searchListIndex = 0;
+ op->searchListIndexLast = 0;
}
Everything is clear now. Follow me for one last time…
The root cause
When receiving a DNS A or AAAA request for a record that ends up being a CNAME, resolvers have to recursively resolve all CNAMEs encountered along the way. This logic is also implemented by mDNSResponder, but gets complicated due to caching.
mDNSResponder supports a caching policy that allows it to return expired records before a fresh answer is available, a feature called “Optimistic DNS”. This allows APIs such as SCNetworkReachability to return verdicts quicker – the risk of a stale DNS resolution is at most an incorrect “Reachable” verdict that will eventually be corrected when the fresh answer comes in.
When mDNSResponder receives a CNAME from the upstream resolver, it will cache it and resolve it further if it’s not the client’s requested record type. However, if a subsequent A or AAAA request for the same domain is issued and the CNAME cache entry has expired, mDNSResponder must be careful not to return it and rewind back to the original domain name to retrieve the most recent value of the record.
When this condition happens, mDNSResponder dispatches an event that signals that no more expired cached records will be returned (mDNSQuestionEvent_NoMoreExpiredRecords). This event is consumed internally to perform the uncached resolution of the expired record.
In mDNSResponder-2200.60.25.0.4, Apple fixed a bug where this CNAME re-resolution was “forgetting” the last used DNS search domain, leading to incorrect queries. The fix introduced an entire new bug, though, which is the subject of this way too long essay ;)
The specific problematic part is the following:
const domainname *domain = mDNSNULL;
if (inQuestion->AppendSearchDomains && (op->searchListIndex >= 0)) // <- incorrect
{
// If we're appending search domains, the DNSQuestion needs to be retried without Optimistic DNS,
// but with the search domain we just used, so restore the search list index to avoid skipping to
// the next search domain.
op->searchListIndex = op->searchListIndexLast;
domain = NextSearchDomain(op);
}This logic fatally assumes that if AppendSearchDomains is truthy (which definitely is if the AlwaysAppendSearchDomains flag is enabled), then a search domain was successfully used to issue the previous request. In reality, even if the flag is enabled, search domains are only appended if requests have previously failed without any search domain. For example:
# demo of mDNSResponder with AlwaysAppendSearchDomains enabled
$ curl totally-random-does-not-exist-blabla.com # uses getaddrinfo() internally which goes
# to mDNSResponder
curl: (6) Could not resolve host: totally-random-does-not-exist-blabla.com
# tcpdump:
# curl does getaddrinfo(), mDNSResponder issues A and AAAA requests
01:48:01.871241 IP6 (...) ::1.53139 > ::1.53: 43674+ A? totally-random-does-not-exist-blabla.com. (58)
01:48:01.871392 IP6 (...) ::1.65287 > ::1.53: 37840+ AAAA? totally-random-does-not-exist-blabla.com. (58)
# upstream resolver says NXDOMAIN
01:48:01.884739 IP6 (...) ::1.53 > ::1.53139: 43674 NXDomain q: A? totally-random-does-not-exist-blabla.com. 0/1/0 ns: com. [15m] SOA a.gtld-servers.net. nstld.verisign-grs.com. 1706060860 1800 900 604800 86400 (131)
# mDNSResponder logic for AlwaysAppendSearchDomains kicks in and retries with search domain
01:48:01.885699 IP6 (...) ::1.63643 > ::1.53: 2637+ A? totally-random-does-not-exist-blabla.com.0.1.168.192.in-addr.arpa. (83)
01:48:01.887567 IP6 (...) ::1.53 > ::1.65287: 37840 NXDomain q: AAAA? totally-random-does-not-exist-blabla.com. 0/1/0 ns: com. [15m] SOA a.gtld-servers.net. nstld.verisign-grs.com. 1706060860 1800 900 604800 86400 (131)
01:48:01.888282 IP6 (...) ::1.64757 > ::1.53: 55811+ AAAA? totally-random-does-not-exist-blabla.com.0.1.168.192.in-addr.arpa. (83)
01:48:01.894787 IP6 (...) ::1.53 > ::1.63643: 2637 NXDomain q: A? totally-random-does-not-exist-blabla.com.0.1.168.192.in-addr.arpa. 0/0/0 (83)
01:48:01.897230 IP6 (...) ::1.53 > ::1.64757: 55811 NXDomain q: AAAA? totally-random-does-not-exist-blabla.com.0.1.168.192.in-addr.arpa. 0/0/0 (83)
# (my system only has one search domain, otherwise this would have continued until the list finished)
A fix could perhaps look like this:
-if (inQuestion->AppendSearchDomains && (op->searchListIndex >= 0))
+if (inQuestion->AppendSearchDomains && (op->searchListIndex >= 0) && (op->searchListIndexLast > 0))
… which would ensure that the search domain list is only advanced if one was used in the first place.
That’s all, folks!
Thanks a lot for bearing through this long write up! I hope reading it was less frustrating than actually trying to debug this entire thing.
If there’s anyone from Apple reading, I reported this as FB13557971. It’s not under the best category (Wi-Fi), but I didn’t find anything better…
Meanwhile, if there’s anyone from Spotify reading, I think using www.spotify.com. (trailing dot) at the end would convince mDNSResponder that this is indeed a fully qualified domain name and no search domain is needed. (I’m not sure I would actually recommend making this change, though, given how magic and opaque SCNetworkReachability is.)
Update (2024-01-26): Turns out there was indeed someone from Spotify reading this! An engineer working on their desktop app stumbled upon this post and was kind enough to let me know that they decided to change their reachability check to use www.spotify.com. (with the trailing dot), which should provide defense-in-depth against further occurrences of this. Thanks a lot - you rock!
Thanks for reading!
Appendix: where was that search domain even coming from?
Great question! Apparently, it’s an “inferred address-based configuration discovery domain”. I have no idea what it’s really used for (I did see some PTR requests issued by mDNSResponder presumably to get an actual domain, but who knows), but the logic that generates it is here.
Footnotes
The common
SCprefix is not a coincidence here - it stands for ‘system configuration’. ↩This is not a joke! ↩
A
SIGHUPcausesmDNSResponderto reload the underlying DNS configuration. ↩This has the side effect of always preferring a fallback resolver if it’s the only one that exposes an encrypted DNS variant, which could be an annoyance for people using custom DNS servers. In such circumstances, I believe blocking queries to
_dns.resolver.arpashould stop this behavior. ↩Spoiler: the “missing logs” had nothing to do with staring at the wrong source code. It’s extremely subtle, but that log message is using level
MDNS_LOG_INFOwhich is not enabled by default (MDNS_LOG_DEFAULTis) ↩